Memtables#
원문 링크
구현할 것은 다음과 같다.
- skiplist 기반의 memtables
- memtable freezing
- LSM read path의 get
Task 1: Skiplist Memtable#
여기서 하려는건 lock-free 동시 write가 가능하면서도 정렬된 in-memory KV를 구현한다. put은 overwrite하고 delete는 tombstone(같은 키에 값을 null) 처리를 한다.
그럼 Memtable은 skiplist만 써야하냐? 아니다. 당연히 다른 자료구조도 사용 가능하다. 다만 trade-off를 이해하고 있어야한다.
| 구조 | 장점 | 단점 |
|---|---|---|
| BTree | cache locality 좋음 | 전역 락 필요 |
| HashMap | write 빠름 | 정렬 안 됨 → flush 비용 |
| Vec(sorted) | scan 빠름 | insert 느림 |
| ART | 메모리 효율 / 빠른 lookup | 구현 복잡 |
| Skiplist | 항상 정렬 / lock-free | cache locality 구림 |
아마 LSM의 컨셉을 익히는데 적절(쉽고 간단하고)해서 고른거 아닐까 싶긴 하다.
Skiplist는 생김새를 보면 알겠지만 다음과 같은 단점이 존재한다.
- 메모리 오버헤드
- 캐시 지역성 최악: 여러 레벨을 따라 다녀서 다른 캐시라인을 타게된다.
- 분기 예측 실패: 레벨이 지옥의 랜덤 게임이다.
- Write Amplification
- range scan에서 별로 (연속적이지 않으니까)
어쨌든 ordered multilevel linked list라고 생각하면 아주 간단하다.
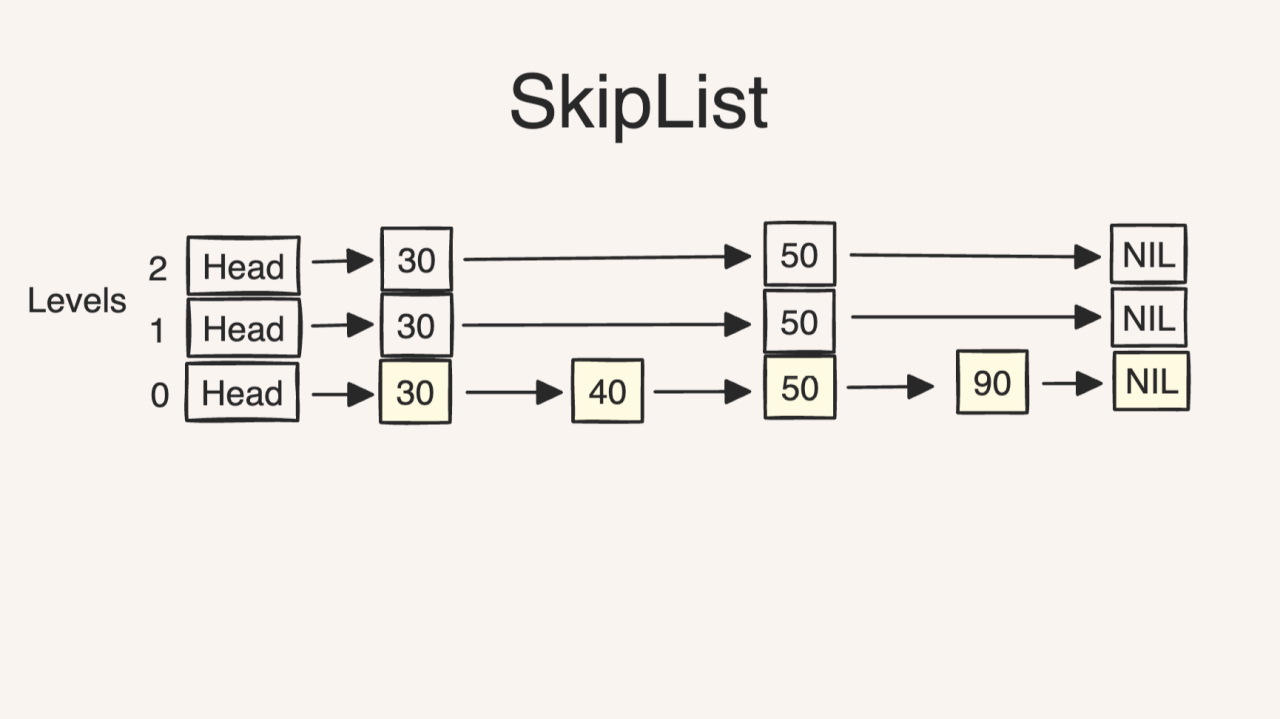
간단한 skiplist 코드. 아니 근데 collapse 기능 없나..
import java.util.concurrent.atomic.AtomicReference
import java.util.concurrent.ThreadLocalRandom
class SkipList(
private val comparator: Comparator<ByteArray> = ByteArrayComparator()
) {
companion object {
const val MAX_LEVEL = 32
private const val PROBABILITY = 0.25
}
class Node(
val key: ByteArray,
@Volatile var value: ByteArray,
level: Int
) {
val forward: Array<AtomicReference<Node?>> = Array(level) { AtomicReference(null) }
}
private val head = Node(ByteArray(0), ByteArray(0), MAX_LEVEL)
private fun randomLevel(): Int {
var level = 1
while (level < MAX_LEVEL && ThreadLocalRandom.current().nextDouble() < PROBABILITY) {
level++
}
return level
}
fun get(key: ByteArray): ByteArray? {
var current = head
for (level in (MAX_LEVEL - 1) downTo 0) {
while (true) {
val next = current.forward[level].get() ?: break
val cmp = comparator.compare(next.key, key)
if (cmp < 0) {
current = next
} else if (cmp == 0) {
return next.value
} else {
break
}
}
}
return null
}
fun put(key: ByteArray, value: ByteArray) {
val update = arrayOfNulls<Node>(MAX_LEVEL)
var current = head
for (level in (MAX_LEVEL - 1) downTo 0) {
while (true) {
val next = current.forward[level].get() ?: break
val cmp = comparator.compare(next.key, key)
if (cmp < 0) {
current = next
} else if (cmp == 0) {
// LWW(Last Write Wins)
next.value = value
return
} else {
break
}
}
update[level] = current
}
val newLevel = randomLevel()
val newNode = Node(key, value, newLevel)
for (level in 0 until newLevel) {
val prev = update[level] ?: head
// retry if CAS failed
while (true) {
val expectedNext = prev.forward[level].get()
newNode.forward[level].set(expectedNext)
if (prev.forward[level].compareAndSet(expectedNext, newNode)) {
break
}
}
}
}
fun iterator(): Iterator<Pair<ByteArray, ByteArray>> = SkipListIterator(head)
private class SkipListIterator(head: Node) : Iterator<Pair<ByteArray, ByteArray>> {
private var current: Node? = head.forward[0].get()
override fun hasNext(): Boolean = current != null
override fun next(): Pair<ByteArray, ByteArray> {
val node = current ?: throw NoSuchElementException()
current = node.forward[0].get()
return node.key to node.value
}
}
}
class ByteArrayComparator : Comparator<ByteArray> {
override fun compare(a: ByteArray, b: ByteArray): Int {
val minLen = minOf(a.size, b.size)
for (i in 0 until minLen) {
val cmp = (a[i].toInt() and 0xFF) - (b[i].toInt() and 0xFF)
if (cmp != 0) return cmp
}
return a.size - b.size
}
}Task 2: Single Memtable in Engine#
엔진에서 항상 mutable memtable은 하나만 존재한다. memtable은 크기 제한이 있고 제한에 도달하면 immutable하게 freeze한다.
memtable은 다음과 같이 구현된다.
class MemTable(val id: Int) {
private val map = SkipList()
private val approximateSize = AtomicLong(0)
fun get(key: ByteArray): ByteArray? {
return map.get(key)
}
fun put(key: ByteArray, value: ByteArray) {
map.put(key, value)
approximateSize.addAndGet((key.size + value.size).toLong())
}
fun approximateSize(): Long = approximateSize.get()
fun iterator(): Iterator<Pair<ByteArray, ByteArray>> = map.iterator()
}- id 값이 있다. 이 값이 작을수록 늙은 memtable이다.
- 내부 자료 구조는 언제든 변경할 수 있도록 숨겼다.
- 사이즈는 근사값이다. 정확한 값을 얻는 것은 성능 저하가 오기 때문이다.
LSM Storage는 크게 두 가지로 나뉜다.
- MiniLSM
- LsmStorageInner
왜 여기서는 이 둘을 분리했을까? 이건 외부에 노출되는 API와 동시성 관리 역할의 분리로 볼 수 있다.
우선 LsmStorageInner의 구현은 다음과 같다.
data class LsmStorageOptions(
val sstSizeBytes: Long = 256L * 1024 * 1024 // 256MB
)
class LsmStorageState(
var memTable: MemTable,
val immutableMemTables: MutableList<MemTable> = mutableListOf()
) {
companion object {
fun create(): LsmStorageState {
return LsmStorageState(memTable = MemTable(0))
}
}
}
class LsmStorageInner(
private val options: LsmStorageOptions = LsmStorageOptions()
) {
private val stateLock = ReentrantReadWriteLock()
private val freezeLock = ReentrantLock()
private val state = LsmStorageState.create()
private val nextId = AtomicInteger(1)
private fun nextSstId(): Int = nextId.getAndIncrement()
}이렇게 간단한 이유는 Write Path와 Read Path 구현을 생략했기 때문이다.
다음은 MiniLSM이다.
class MiniLSM private constructor(
private val inner: LsmStorageInner
) {
companion object {
fun open(options: LsmStorageOptions = LsmStorageOptions()): MiniLSM {
return MiniLSM(LsmStorageInner(options))
}
}
fun get(key: ByteArray): ByteArray? = inner.get(key)
fun put(key: ByteArray, value: ByteArray) = inner.put(key, value)
fun delete(key: ByteArray) = inner.delete(key)
fun forceFreeze() = inner.forceFreeze()
}진짜로 외부로 노출되는 API뿐이다. 지금은 싸가지 없게 ByteArray를 쓰고 있지만 인간 친화적인 API를 위해서 이 부분에서 변환하는 것도 선택이 될 수 있다.
Task 3: Write Path - Freezing a Memtable#
memtable은 무한하게 커질 수 없다. 일정 사이즈(여기서는 256MB)를 넘어가면:
freeze -> flush to disk
앞에서도 이야기 했지만 soft limit이다. 사이즈를 정확히 측정하면 속도 저하가 발생한다.
그럼 대략적으로는 어떻게 계산하냐? key + value 바이트 크기 누적 정도로 처리한다.
와! 그럼같은 key로 두 번 put하면요? -> size는 두 번 카운트 하자.
어쨌든 용량을 넘어가면 force_freeze_memtable를 호출해서 더 이상 여기에는 못쓰게 한다.
import kotlin.concurrent.read
import kotlin.concurrent.withLock
import kotlin.concurrent.write
private fun tryFreezeMemTable() {
freezeLock.withLock {
val currentSize = stateLock.read {
state.memTable.approximateSize()
}
if (currentSize >= options.sstSizeBytes) {
forceFreeze()
}
}
}
private fun forceFreeze() {
val newMemTableId = nextSstId()
val newMemTable = MemTable(newMemTableId)
stateLock.write {
state.immutableMemTables.add(0, state.memTable)
state.memTable = newMemTable
}
}여기서 state를 보호하기 위한 장치로 RWLock을 사용했다.
CoW 기반 동시성 관리를 위한 친구인데, 읽기는 자유롭게 일관된 상태를 보게하고 memtable 교체를 할 때는 write는 보호되어야 하기 때문에 stateLock.write이 등장함.
RWLock은 문서를 읽어보자.
돌아와서 Task 3에 좋은 부분이 있는데 다음과 같다.
Now when we freeze the memtable, no other threads could have access to the LSM state for several milliseconds, which creates a spike of latency. To solve this problem, we can put I/O operations outside of the lock region.
제발 lock 밖에 I/O를 두라고. 이건 사실 transaction scope내에 외부 API이나 오랜 시간이 걸리는 file I/O등을 아무렇지 않게 작성하는 싸이코패스들이 봐야 할 글이다.
Then, we do not have costly operations within the state write lock region. Now, consider the case that the memtable is about to reach the capacity limit and two threads successfully put two keys into the memtable, both of them discovering the memtable reaches capacity limit after putting the two keys. They will both do a size check on the memtable and decide to freeze it. In this case, we might create one empty memtable which is then immediately frozen.
이건 freeze 시 발생할 수 있는 race condition에 대한 해결 방법을 이야기한다. 여러 스레드가 동시에 capacity 초과를 감지해서 freeze를 하다가 비어 있는 memtable을 조질 수 있다.
따라서 이 부분은 다음과 같이 해결할 수 있다.
put() {
// read lock에서 put + 용량 체크
if capacity 초과 {
state_lock.lock()
if 다시 확인해서 진짜 초과면
freeze
}
}실제 구현 버전은 다음과 같다.
fun put(key: ByteArray, value: ByteArray) {
val needsFreeze = stateLock.read {
state.memTable.put(key, value)
state.memTable.approximateSize() >= options.sstSizeBytes
}
if (needsFreeze) {
tryFreezeMemTable()
}
}
private fun tryFreezeMemTable() {
freezeLock.withLock {
val currentSize = stateLock.read {
state.memTable.approximateSize()
}
if (currentSize >= options.sstSizeBytes) {
forceFreeze()
}
}
}여러 스레드가 접근 하는 시나리오에 대해 다음과 같이 정리를 해봤다.
- read lock으로 동결이 필요한지 체크하고 (
thread A) - 그럼 이제 실제로 시도를 해본다. (
thread A) - 나 thread B인데 freeze함 ㅅㄱ; (
thread B) - freezeLock으로 진입한다. (
thread A) - stateLock으로 read를 해서 사이즈를 봤더니 용량이 넉넉하다. memtable이 교체되었다는 뜻이다. 따라서 freeze가 필요가 없다. (
thread A)
이렇게 하면 race condition 상태에서 비어있는 memtable이 얼어붙는 참사가 발생하지 않는다.
실질적인 freeze 부분은 앞에서도 소개했지만 다시 보자.
private fun forceFreeze() {
val newMemTableId = nextSstId()
val newMemTable = MemTable(newMemTableId)
stateLock.write {
state.immutableMemTables.add(0, state.memTable)
state.memTable = newMemTable
}
}- 다음 ID를 atomic integer로 thread-safe하게 채번한다.
- 새 Memtable을 만들어 이 id를 부여한다.
- stateLock(RWLock)의 write lock으로 안전하게 교체한다.
Task 4: Read Path - Get#
overview에서 언급한 것과 같이 new to old순으로 memtable을 읽는다.
fun get(key: ByteArray): ByteArray? {
return stateLock.read {
state.memTable.get(key)?.let { value ->
return@read if (value.isEmpty()) null else value
}
for (immutableMemTable in state.immutableMemTables) {
immutableMemTable.get(key)?.let { value ->
return@read if (value.isEmpty()) null else value
}
}
null
}
}자명하므로 설명 생략
Test Your Understanding#
Test Your Understanding
- Why doesn’t the memtable provide a delete API?
memtable에서만 지우면 SST에 남아 있는게 살아난다. 여러 SST에 걸쳐 같은 키가 나타날 수 있다. 이게 tombstone write put(key, null)
- Does it make sense for the memtable to store all write operations instead of only the latest version of a key? For example, the user puts a->1, a->2, and a->3 into the same memtable.
foo->1, foo->2, foo->3 다 저장해야함? 보통은 아니다. memtable은 최신값만 유지하는 mutable view 모든 버전이 저장되면 메모리가 터지고 read가 느려지고 flush 시 중복 정리가 필요해지고 나라가 무너지고 그리고 WAL이 있기 때문에 WAL이 모든 것을 기록하고 실질적인 최신 상태는 memtable이 갖고 있다.
- Is it possible to use other data structures as the memtable in LSM? What are the pros/cons of using the skiplist?
가능함. 여기서 skiplist인 이유는 1) 간단하고 2) 정렬되어 있고 3) lock-free insert이고. skiplist? 단점은 있다 물론. 그건 위에서 설명함.
- Why do we need a combination of state and state_lock? Can we only use state.read() and state.write()?
필요함. state -> snapshot 교체 용도, state_lock -> freeze, flush 같은 중대한 변경은 serialize하게 변경해야함. state.write만 사용한다면 IO에 write lock이 생기고 latency spike가 생김.
- Why does the order to store and to probe the memtables matter? If a key appears in multiple memtables, which version should you return to the user?
중요함. 최신 write가 먼저 나와야하기 때문. mutable/immutable memtable에 걸쳐 동일 key가 존재할 수 있기 때문. 그래서 최신의 memtable부터 읽으려면 mutable부터 읽는게 최신임
- Is the memory layout of the memtable efficient / does it have good data locality? (Think of how Byte is implemented and stored in the skiplist…) What are the possible optimizations to make the memtable more efficient?
계속 말하지만 locality 박살. 노드가 힙에 흩어져 있어 포인터 지옥이고 value도 또 따로 있음. arena allocation이 떠오른다. malloc/free는 코스트가 크고 정합성 때문에 락도 개입되면 추가적으로 느려짐. 그래서 큰 덩어리로 할당해두면 cache locality도 좋고 추가적인 할당/해제를 안해서 좋기도 함. rocksdb도 실제로 memtable의 구현체가 다양하다. 문서
- So we are using parking_lot locks in this course. Is its read-write lock a fair lock? What might happen to the readers trying to acquire the lock if there is one writer waiting for existing readers to stop?
RWLock은 writer가 대기 걸면 reader가 블록이 되기 때문에 fair하진 않음. writer starvation을 막기 위함인데 대신 reader latency가 튀어버린다.
- After freezing the memtable, is it possible that some threads still hold the old LSM state and wrote into these immutable memtables? How does your solution prevent it from happening?
그러지 말라고 freezing하는거잖슴!
- There are several places that you might first acquire a read lock on state, then drop it and acquire a write lock (these two operations might be in different functions but they happened sequentially due to one function calls the other). How does it differ from directly upgrading the read lock to a write lock? Is it necessary to upgrade instead of acquiring and dropping and what is the cost of doing the upgrade?
LSM에선 짧은 critical section을 가져가기 위해 노력함.
나의 요약#
- LSM에서는 write를 직렬화하고 read는 막지 않는다.
- 그럼 write-intensive한 환경에서 유리하다는 말을 할 수 없지 않냐?
- 아님. throughput에 병목을 주는게 아님. 전통적인 lock 기반 자료구조의 직렬화는 느릴 수 있지만 이 친구는 아님
- write path를 생각해보면 1) WAL append 2) memtable insert 3) freeze trigger 판단 4) state 변경(짧은 critical section)
- 여기서 직렬화되는건 state 변경인데 이 부분은 아주 짧음.
- 그래서 실질적인 write의 대부분은 직렬화 안되고, 그 부분 마저도 포인터 교체
- 그리고 write도 메모리에 갈김
- 위의 요약을 읽고 B-Tree가 하는 일을 떠올려보자. write가 곧 구조 수정이기 때문에 코스트가 비교가 안된다. (심지어 random I/O)
- 극단적 요약: log 이어 붙이는 시스템 (Kafka처럼)