Memtables#
Original link
What we’ll implement:
- Skiplist-based memtables
- Memtable freezing
- LSM read path’s get
Task 1: Skiplist Memtable#
The goal here is to implement a sorted in-memory KV store that supports lock-free concurrent writes. Put overwrites existing values, and delete is handled via tombstones (writing null for the same key).
So does the memtable have to use a skiplist? No. Other data structures are perfectly fine. You just need to understand the trade-offs.
| Structure | Pros | Cons |
|---|---|---|
| BTree | Good cache locality | Requires global lock |
| HashMap | Fast writes | Not sorted → expensive flush |
| Vec(sorted) | Fast scan | Slow insert |
| ART | Memory efficient / fast lookup | Complex implementation |
| Skiplist | Always sorted / lock-free | Poor cache locality |
I suspect they chose the skiplist because it’s suitable (easy and simple) for learning the concepts of LSM. If you look at the shape of a skiplist, you’ll notice the following drawbacks:
- Memory overhead
- Worst-case cache locality: traversing multiple levels hits different cache lines
- Branch prediction failures: levels are a hellish random game
- Write amplification
- Poor for range scans (since it’s not contiguous)
Anyway, you can think of it simply as an ordered multilevel linked list.
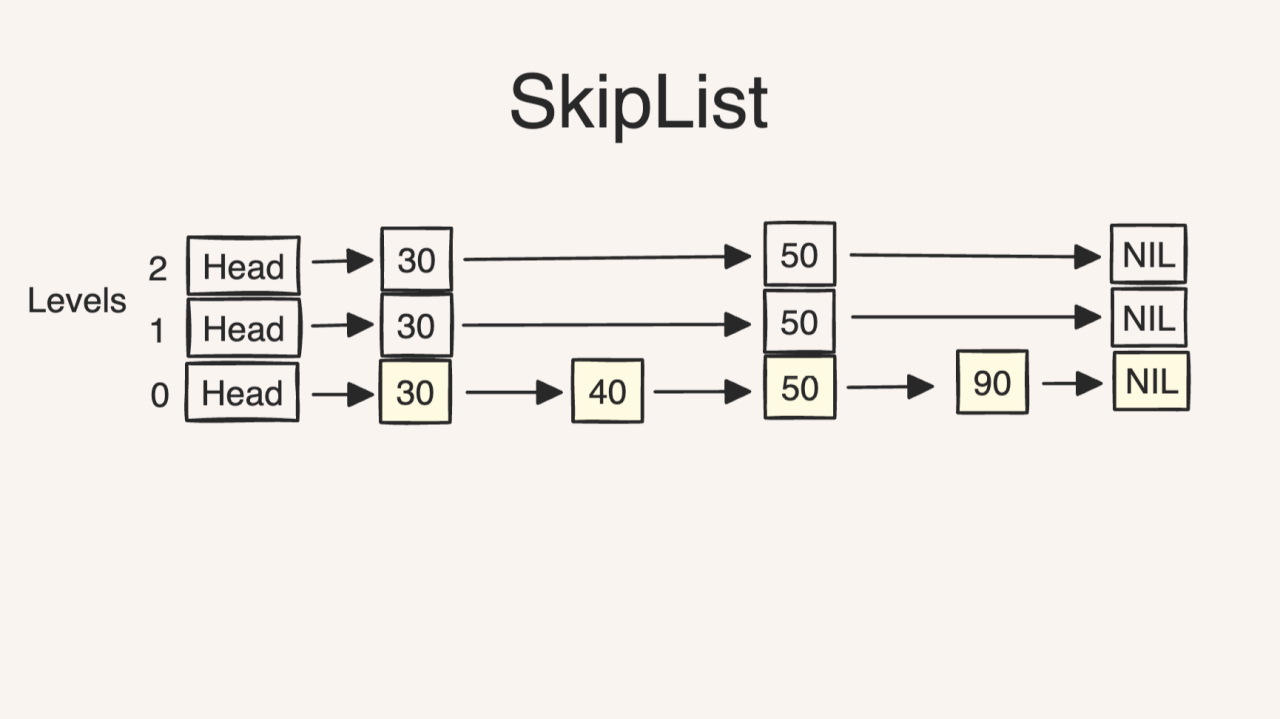
A simple skiplist implementation. I wish there was a collapse feature though..
import java.util.concurrent.atomic.AtomicReference
import java.util.concurrent.ThreadLocalRandom
class SkipList(
private val comparator: Comparator<ByteArray> = ByteArrayComparator()
) {
companion object {
const val MAX_LEVEL = 32
private const val PROBABILITY = 0.25
}
class Node(
val key: ByteArray,
@Volatile var value: ByteArray,
level: Int
) {
val forward: Array<AtomicReference<Node?>> = Array(level) { AtomicReference(null) }
}
private val head = Node(ByteArray(0), ByteArray(0), MAX_LEVEL)
private fun randomLevel(): Int {
var level = 1
while (level < MAX_LEVEL && ThreadLocalRandom.current().nextDouble() < PROBABILITY) {
level++
}
return level
}
fun get(key: ByteArray): ByteArray? {
var current = head
for (level in (MAX_LEVEL - 1) downTo 0) {
while (true) {
val next = current.forward[level].get() ?: break
val cmp = comparator.compare(next.key, key)
if (cmp < 0) {
current = next
} else if (cmp == 0) {
return next.value
} else {
break
}
}
}
return null
}
fun put(key: ByteArray, value: ByteArray) {
val update = arrayOfNulls<Node>(MAX_LEVEL)
var current = head
for (level in (MAX_LEVEL - 1) downTo 0) {
while (true) {
val next = current.forward[level].get() ?: break
val cmp = comparator.compare(next.key, key)
if (cmp < 0) {
current = next
} else if (cmp == 0) {
// LWW(Last Write Wins)
next.value = value
return
} else {
break
}
}
update[level] = current
}
val newLevel = randomLevel()
val newNode = Node(key, value, newLevel)
for (level in 0 until newLevel) {
val prev = update[level] ?: head
// retry if CAS failed
while (true) {
val expectedNext = prev.forward[level].get()
newNode.forward[level].set(expectedNext)
if (prev.forward[level].compareAndSet(expectedNext, newNode)) {
break
}
}
}
}
fun iterator(): Iterator<Pair<ByteArray, ByteArray>> = SkipListIterator(head)
private class SkipListIterator(head: Node) : Iterator<Pair<ByteArray, ByteArray>> {
private var current: Node? = head.forward[0].get()
override fun hasNext(): Boolean = current != null
override fun next(): Pair<ByteArray, ByteArray> {
val node = current ?: throw NoSuchElementException()
current = node.forward[0].get()
return node.key to node.value
}
}
}
class ByteArrayComparator : Comparator<ByteArray> {
override fun compare(a: ByteArray, b: ByteArray): Int {
val minLen = minOf(a.size, b.size)
for (i in 0 until minLen) {
val cmp = (a[i].toInt() and 0xFF) - (b[i].toInt() and 0xFF)
if (cmp != 0) return cmp
}
return a.size - b.size
}
}Task 2: Single Memtable in Engine#
The engine always has exactly one mutable memtable. A memtable has a size limit, and when it reaches that limit, it’s frozen into an immutable state.
The memtable is implemented as follows:
class MemTable(val id: Int) {
private val map = SkipList()
private val approximateSize = AtomicLong(0)
fun get(key: ByteArray): ByteArray? {
return map.get(key)
}
fun put(key: ByteArray, value: ByteArray) {
map.put(key, value)
approximateSize.addAndGet((key.size + value.size).toLong())
}
fun approximateSize(): Long = approximateSize.get()
fun iterator(): Iterator<Pair<ByteArray, ByteArray>> = map.iterator()
}- There’s an id field. A smaller id means an older memtable.
- The internal data structure is hidden so it can be swapped out at any time.
- The size is approximate. Getting an exact value would incur a performance penalty.
LSM Storage is broadly divided into two parts:
- MiniLSM
- LsmStorageInner
Why are these two separated here? This can be seen as a separation of externally exposed API and concurrency management responsibilities.
First, the LsmStorageInner implementation:
data class LsmStorageOptions(
val sstSizeBytes: Long = 256L * 1024 * 1024 // 256MB
)
class LsmStorageState(
var memTable: MemTable,
val immutableMemTables: MutableList<MemTable> = mutableListOf()
) {
companion object {
fun create(): LsmStorageState {
return LsmStorageState(memTable = MemTable(0))
}
}
}
class LsmStorageInner(
private val options: LsmStorageOptions = LsmStorageOptions()
) {
private val stateLock = ReentrantReadWriteLock()
private val freezeLock = ReentrantLock()
private val state = LsmStorageState.create()
private val nextId = AtomicInteger(1)
private fun nextSstId(): Int = nextId.getAndIncrement()
}The reason it’s this simple is that the Write Path and Read Path implementations are omitted. Next is MiniLSM:
class MiniLSM private constructor(
private val inner: LsmStorageInner
) {
companion object {
fun open(options: LsmStorageOptions = LsmStorageOptions()): MiniLSM {
return MiniLSM(LsmStorageInner(options))
}
}
fun get(key: ByteArray): ByteArray? = inner.get(key)
fun put(key: ByteArray, value: ByteArray) = inner.put(key, value)
fun delete(key: ByteArray) = inner.delete(key)
fun forceFreeze() = inner.forceFreeze()
}It’s purely the externally exposed API. Right now it rudely uses ByteArray, but for a human-friendly API, converting at this layer could be an option.
Task 3: Write Path - Freezing a Memtable#
A memtable cannot grow indefinitely. When it exceeds a certain size (256MB in this case):
freeze -> flush to disk
As mentioned earlier, this is a soft limit. Measuring the size precisely would cause performance degradation. So how do we calculate it approximately? By accumulating the byte sizes of keys and values.
Wait, what if you put the same key twice? -> Count the size twice.
Anyway, when the capacity is exceeded, we call force_freeze_memtable to prevent further writes to it.
import kotlin.concurrent.read
import kotlin.concurrent.withLock
import kotlin.concurrent.write
private fun tryFreezeMemTable() {
freezeLock.withLock {
val currentSize = stateLock.read {
state.memTable.approximateSize()
}
if (currentSize >= options.sstSizeBytes) {
forceFreeze()
}
}
}
private fun forceFreeze() {
val newMemTableId = nextSstId()
val newMemTable = MemTable(newMemTableId)
stateLock.write {
state.immutableMemTables.add(0, state.memTable)
state.memTable = newMemTable
}
}Here, an RWLock is used as a mechanism to protect the state.
It’s a friend for CoW-based concurrency management — reads freely see a consistent state, and when swapping the memtable, writes must be protected, hence stateLock.write.
For RWLock, check the documentation.
Coming back to Task 3, there’s a great passage:
Now when we freeze the memtable, no other threads could have access to the LSM state for several milliseconds, which creates a spike of latency. To solve this problem, we can put I/O operations outside of the lock region.
Please, keep I/O outside the lock. This is something that psychopaths who casually write external API calls or long-running file I/O inside a transaction scope really need to read.
Then, we do not have costly operations within the state write lock region. Now, consider the case that the memtable is about to reach the capacity limit and two threads successfully put two keys into the memtable, both of them discovering the memtable reaches capacity limit after putting the two keys. They will both do a size check on the memtable and decide to freeze it. In this case, we might create one empty memtable which is then immediately frozen.
This discusses solving a race condition that can occur during freezing. Multiple threads may simultaneously detect a capacity overflow and attempt to freeze, potentially freezing an empty memtable. This can be solved as follows:
put() {
// put + capacity check under read lock
if capacity exceeded {
state_lock.lock()
if double-check confirms it's actually exceeded
freeze
}
}The actual implementation looks like this:
fun put(key: ByteArray, value: ByteArray) {
val needsFreeze = stateLock.read {
state.memTable.put(key, value)
state.memTable.approximateSize() >= options.sstSizeBytes
}
if (needsFreeze) {
tryFreezeMemTable()
}
}
private fun tryFreezeMemTable() {
freezeLock.withLock {
val currentSize = stateLock.read {
state.memTable.approximateSize()
}
if (currentSize >= options.sstSizeBytes) {
forceFreeze()
}
}
}Here’s a walkthrough of the multi-threaded access scenario:
- Check under read lock whether freezing is needed (
thread A) - Now actually attempt it (
thread A) - Hey, I’m thread B and I just froze it, peace out (
thread B) - Enter freezeLock (
thread A) - Read the size under stateLock — turns out there’s plenty of room. This means the memtable was already swapped. So no freeze is needed. (
thread A)
This prevents the disaster of an empty memtable being frozen under a race condition.
The actual freeze part was introduced earlier, but let’s look at it again.
private fun forceFreeze() {
val newMemTableId = nextSstId()
val newMemTable = MemTable(newMemTableId)
stateLock.write {
state.immutableMemTables.add(0, state.memTable)
state.memTable = newMemTable
}
}- Assign the next ID in a thread-safe manner using an atomic integer.
- Create a new Memtable with this ID.
- Safely swap it under stateLock (RWLock)’s write lock.
Task 4: Read Path - Get#
As mentioned in the overview, memtables are read from newest to oldest.
fun get(key: ByteArray): ByteArray? {
return stateLock.read {
state.memTable.get(key)?.let { value ->
return@read if (value.isEmpty()) null else value
}
for (immutableMemTable in state.immutableMemTables) {
immutableMemTable.get(key)?.let { value ->
return@read if (value.isEmpty()) null else value
}
}
null
}
}Self-explanatory, so no further explanation needed.
Test Your Understanding#
Test Your Understanding
- Why doesn’t the memtable provide a delete API?
If you only delete from the memtable, entries surviving in the SSTs would resurface. The same key can appear across multiple SSTs. This is why we do a tombstone write. put(key, null)
- Does it make sense for the memtable to store all write operations instead of only the latest version of a key? For example, the user puts a->1, a->2, and a->3 into the same memtable.
Should we store foo->1, foo->2, foo->3? Usually not. The memtable is a mutable view that keeps only the latest value. If all versions were stored, memory would explode, reads would slow down, flush would need deduplication, and the world would crumble. Besides, since we have WAL, the WAL records everything while the memtable holds the actual latest state.
- Is it possible to use other data structures as the memtable in LSM? What are the pros/cons of using the skiplist?
Yes, it’s possible. The reason for using a skiplist here is: 1) it’s simple, 2) it’s sorted, and 3) it supports lock-free inserts. Skiplist? It has downsides, of course. Those were explained above.
- Why do we need a combination of state and state_lock? Can we only use state.read() and state.write()?
Yes, we need both. state -> for snapshot swapping, state_lock -> critical changes like freeze and flush must be serialized. If you only use state.write, I/O ends up under the write lock, causing latency spikes.
- Why does the order to store and to probe the memtables matter? If a key appears in multiple memtables, which version should you return to the user?
It matters. The latest write must come first. The same key can exist across mutable and immutable memtables. So to read the latest memtable first, you start from the mutable one — that’s where the newest data lives.
- Is the memory layout of the memtable efficient / does it have good data locality? (Think of how Byte is implemented and stored in the skiplist…) What are the possible optimizations to make the memtable more efficient?
As repeatedly mentioned, locality is destroyed. Nodes are scattered across the heap in a pointer nightmare, and values are stored separately too. Arena allocation comes to mind. malloc/free is costly, and if locks are involved for correctness, it gets even slower. So pre-allocating a large chunk improves both cache locality and eliminates additional allocation/deallocation overhead. RocksDB actually has various memtable implementations. Documentation
- So we are using parking_lot locks in this course. Is its read-write lock a fair lock? What might happen to the readers trying to acquire the lock if there is one writer waiting for existing readers to stop?
RWLock isn’t fair because readers get blocked when a writer is waiting. This prevents writer starvation, but reader latency can spike as a result.
- After freezing the memtable, is it possible that some threads still hold the old LSM state and wrote into these immutable memtables? How does your solution prevent it from happening?
That’s exactly why we freeze it!
- There are several places that you might first acquire a read lock on state, then drop it and acquire a write lock (these two operations might be in different functions but they happened sequentially due to one function calls the other). How does it differ from directly upgrading the read lock to a write lock? Is it necessary to upgrade instead of acquiring and dropping and what is the cost of doing the upgrade?
In LSM, the effort is to keep critical sections short.
My Summary#
- In LSM, writes are serialized while reads are not blocked.
- Then can’t we say it’s advantageous for write-intensive workloads?
- Actually, we can. It doesn’t bottleneck throughput. Traditional lock-based data structure serialization can be slow, but this one isn’t.
- Think about the write path: 1) WAL append 2) memtable insert 3) freeze trigger check 4) state change (short critical section)
- What gets serialized here is the state change, and that part is very short.
- So the bulk of actual writes are not serialized, and even the serialized part is just a pointer swap.
- Plus, writes go straight to memory.
- After reading the summary above, think about what a B-Tree does for writes. Since a write directly modifies the structure, the cost is incomparable. (And it’s random I/O on top of that.)
- Extreme summary: A log-append system (like Kafka)